


A Friendly Exploration of Transformers
Approaching a conceptual understanding of the Transformer architecture in the context of Large Language Models.

Introduction
Hey, everyone!
Recently, I’ve found myself consumed by the desire to understand Transformers.
Originally proposed in the now famous paper Attention Is All You Need (Vaswani et al., 2017) the Transformer is the underlying architecture supporting most modern Large Language Models (LLMs).
At first glance, a diagram like the one shown below can seem pretty overwhelming.
I know it was for me, at first.

The goal of this article is to explain this architecture from a high level in the context of large language models. Transformers have also been used in other domains, such as image, video, and audio, but they are outside of the scope of this article.
This article is as much an exercise in strengthening my own understanding as it is a desire to communicate it to others in an easily understood, simplified manner.
Given this goal (and my own level of experience), this article will not capture the full breadth of the mathematical or deeper machine learning aspects of the architecture.
While I will touch on some machine learning concepts, I am working towards more of a representational, rather than intricate, explanation of the architecture.
My aim is to provide helpful analogies that can be used as on-ramps towards a conceptual understanding of the Transformer architecture.
Let’s get started!
Tokenization

First things first. In order for our input sequence to be properly processed by the Transformer model, it must be split into manageable elements. This process is handled by a component known as a Tokenizer.
Tokenization breaks down our input sequence into discrete elements known as tokens:
Original: "The cat sat on the mat."
Tokens: ["The", "cat", "sat", "on", "the", "mat", "."]
This example is based on a simple sentence, however it should be noted that tokenization does not always result in whole word tokens. Often, words and symbols are broken into sub-tokens when passed through to the model.
Below is an example of how a longer word may be broken into multiple tokens:
Original: "Characterization"
Tokens: [“Chara“, “cter”, “ization” ]
However, tokenization is not a one-size-fits-all process. Different models have their own unique methods of tokenizing input sequences, tailored to their specific domain.
Each tokenizer has its own vocabulary, which is its comprehensive set of tokens that it can use to understand and generate text.
For example, Meta’s Llama-2 series of language models have a vocabulary size of 32,000 tokens.
In this context, vocabulary primarily refers to explicit tokens, including split words and symbols as previously described, rather than a collection of whole words.
Nonetheless, some whole words may still be included in the tokenizer's vocabulary.
Embeddings
In order for our model to comprehend our tokens, we translate them into embeddings.
Embeddings are how the model actually “sees” the input sequence, storing not only the concepts themselves but their contextual relationships as well.
Think of embeddings as the Rosetta Stone for our model, translating tokens like "Cat" and "Mat" into vectors like [1, -3, 0, ...] and [4, 9, 2, ...], respectively.
Embeddings are stored in a high dimensional space where similar concepts and meanings are grouped closely together. These dimensions can get quite large, as they need to represent a wide array of relational aspects, so I’ve kept our example small here for simplicity’s sake.
In the diagram below, we can see that “Feline”, “Cat”, and “Kitten” are all located in a similar region, whereas “Mat” is located much further away, due to its dissimilarity to the other concepts.

This spatial arrangement allows the model to compare embeddings against each other, allowing it to increase its understanding of the content and context of each token, and ultimately it is these embeddings that inform the output generation process.
Positional Encoding
In language, word order is critical when trying to understand the context of a sentence.
Positional Encoding is the method by which the Transformer model comes to understand word order. By adding a positional vector to each token’s embedding that represents its order in the input sequence, the model lays the groundwork for contextual understanding.
We can think of these positional encodings as labels that accompany our embeddings, stating their place in the input sequence.
In the diagram below we can see that each token is represented by its embedding, as well as an associated positional vector. Please note however, that this is purely illustrative, and positional vectors are much more complex in structure, matching the size of the token embedding that they are associated with.
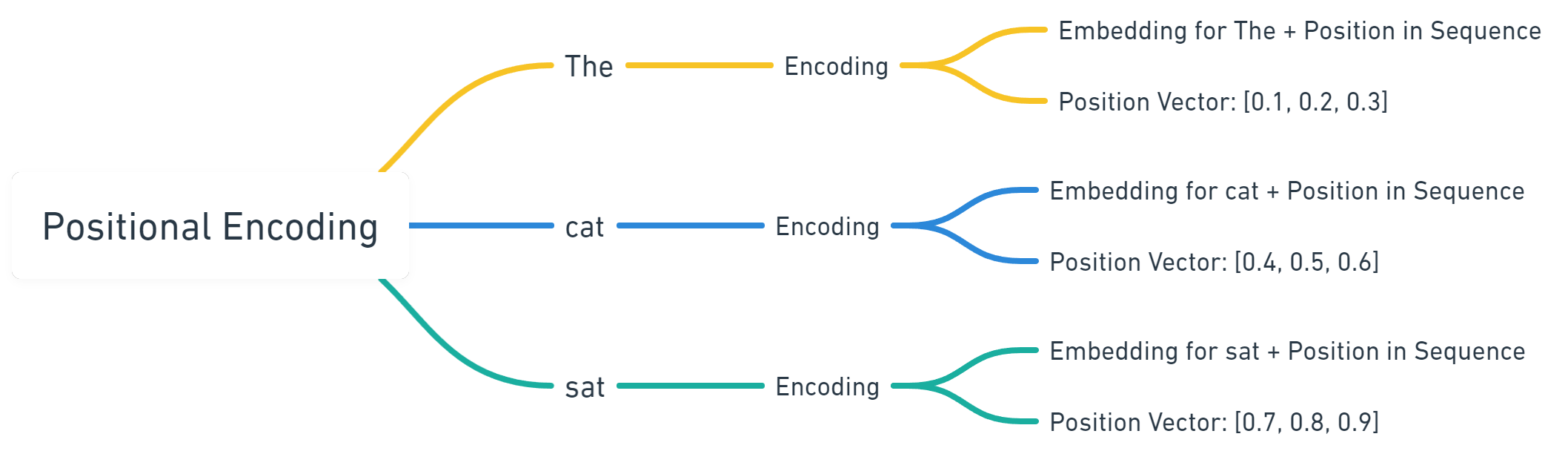
Positional Encoding is one aspect of the architecture that helps the model to understand the difference between “The cat sat on the mat.” and “The mat sat on the cat.”
Attention Mechanism
Transformers use a mechanism known as self-attention to determine the context (and the importance of the context) that each token in an input sequence has to itself, as well as every other token in the sequence.
We’ll touch on how this works in greater detail in the Queries, Keys, and Values section next.

This attention mechanism allows Transformers to understand the relationships between tokens regardless of their distance in the sequence, unlike predecessors like RNNs (Recurrent Neural Networks).
RNNs often struggled with long passages of text, relying on sequential understanding with dramatically smaller context windows. These smaller, sequentially dependent context windows often led to problems such as catastrophic forgetting, where information from earlier in a sequence would be forgotten by the end of a sequence.
Attention is at the core of why Transformers have become as ubiquitous as they are in the modern era, offering a significant boost in quality when generating (and understanding) long, coherent passages of text.
Queries, Keys, and Values
Queries, Keys, and Values are the core elements used by the attention mechanism to understand and express the different contextual and relational aspects of each token in an input sequence.
Their actual interactions within the architecture are pretty complex, so I’ll try to communicate their functions via high-level analogies.
Please keep in mind however, that these are illustrative simplifications and don’t cover the true complexities of their interactions within the architecture.
Query
In our example sentence, “The cat sat on the mat.”, we can think of a Query as asking the question “What is the cat doing?”
In practice, each token has a Query vector that is used to help discover its role and importance in the context of our input sequence.
For instance, the Query helps the model focus on the action “sat” as it relates to “cat”.
Key
Keys can be seen as a beacon pointing to the information stored by each token embedding in our input sequence, which helps guide Queries to the “answers” that they are looking for.
In practice, each token has a Key vector, which the Queries use when attempting to locate and understand its context. This process helps the model understand the relationships and relevance between each token of the input sequence.
For instance, the Key for “sat” in “The cat sat on the mat.” acts as a beacon, highlighting its role in the sequence. This guides the Query associated with “cat” to focus on “sat” as the action that is being performed by the “cat”.
Value
A Value can be thought of as the information or content of each token, as highlighted by the Key beacon.
In practice, Queries, guided by Keys, assess these Values and arrive at the “answer” to the question of “How important is this token to the context of the input sequence?”
For instance, the Value of “sat” provides the specific information that the Query needs, confirming that it is the action being taken by the “cat” in our sequence.
Attention’s Role
The attention mechanism uses the interplay of QKVs to discern which aspects of the input are contextually significant.
This process can be thought of as sharpening the clarity of the most relevant elements while softly blurring the less relevant parts.
Internally, this is represented as an attention score that is derived for each token, but for the purposes of this article we’ll avoid that level of complexity.
In summary, Queries pose questions about tokens, Keys highlight where to look for relevant information, and Values provide the substance that answers those questions.
QKVs work together towards a dynamic understanding and prioritization of different parts of our input sequence during the model's processing.
This is ultimately a hyper-simplified representation of what is a pretty complex aspect of the Transformer architecture.
Training Transformers
Now that we understand how Transformers process input sequences, let's explore how these models are trained to perform complex language tasks.
Transformers typically undergo two main phases of training, pre-training and fine-tuning.
Pre-training establishes a Transformer model’s foundational knowledge of language, via the application of the attention mechanism over an extensive dataset of raw text, often tens of terabytes in size, generally scraped from the internet.
The average individual is unlikely to have the resource available to pre-train their own model from scratch due to the intense amount of data and computational resource required. Pre-trained models are typically funded by corporations such as Google, Meta, Stability AI, and OpenAI. These are known as Foundation Models.
After pre-training, foundation models are often fine-tuned on domain specific data related to particular tasks like translation, question-answering, coding, or content writing. Fine-tuning allows the model to adapt its broad language understanding to the nuances of these domain specific tasks.
Fine-tuning is far more accessible for your average company or individual, often requiring significantly less data and computational resource than pre-training.
During Training
Transformers learn via processes known as backpropagation and gradient descent.
Backpropagation can be thought of as the model learning from its mistakes. During training, the model makes predictions, compares them to an evaluation set (what we’d like our outputs to look like), and then adjusts itself to try and make clearer predictions next time.
This is guided by a loss function, which measures the difference (or “error”) between the model's current output and the expected output in the evaluation set.

Gradient descent can be thought of as teaching someone how to walk down a hill blindfolded, with the goal of reaching flat land. This flat land is where you want to be, because that’s where your house is, and being in your house gives you the most efficient access to your library, where all of your knowledge is kept.

Each step that is taken is analyzed based on the way that it “feels.”
If it feels like the slope is heading upward, you take a step back, if it feels like the slope is heading downward, you take a step forward.
In this analogy, the slope is our loss function, and the size of the steps being taken is our learning rate.
If the steps taken are too large, you might miss the valley and overshoot your house, which means its going to be a lot harder for you to access your knowledge.
If the steps taken are too small, you’ll never reach your house, which is just as bad!
The goal of training is to minimize loss, while avoiding issues like overfitting, where the model becomes too tailored to the training data and performs poorly on new, unseen data. Overfitting can be thought of as being stuck inside of your library, only ever capable of responding to questions with the knowledge stored in its books, unable to think outside of the box.

If, after training, a model responds well to questions or tasks that were not explicitly present in its training set, this is known as the model having generalized well. We can think of generalization as the model being able to efficiently apply its knowledge to a wide range of tasks, rather than only being capable of providing stilted or repetitive answers, which may be the case if the model has been overfit.

Often, training is done over several runs where the results of each are compared to each other, carefully adjusting settings known as hyperparameters in the hope of arriving at a resulting model that generalizes well.
Introduction to Encoders and Decoders
Before we get much further, it's important that we understand two fundamental components that form the basis of these models: encoders and decoders.
It's also important to note that Transformers consist of many stacks of these encoders and decoders, with each layer contributing to the processing of the input and output sequence.
What is an Encoder?
An encoder is a component that processes input data, designed to encode information into embeddings, which we covered earlier in this article.
What is a Decoder?
A decoder, on the other hand, is responsible for converting embeddings from their high-dimensional representations into the desired output text based on the input context.
Encoder-Decoder Models
In an encoder-decoder model, these two components work in tandem: the encoder first processes the input into intermediate embeddings, and then the decoder uses this processed information, alongside its learned embeddings, to inform the generation of the output text.
This is the traditional Transformer architecture, and the one originally put forward in the Attention Is All You Need paper, which was initially focused on the architecture as a way to improve language translation.
A simplified way of looking at this might be that encoders in an encoder-decoder structure allow the model to “think” deeper about their inputs, which may be more suited for domain specific applications (such as complex translation use-cases), at the cost of speed and scalability.
Encoder-decoder models also benefit from there being an explicit delineation between the input sequence and the output sequence. This helps prevent the initial input (for example, a text prompt) from leaking into the generated output, as can sometimes happen with decoder-only models.
If we use the language translation domain as our analogy, its like hearing the source language, writing it down, studying it, and then translating it to the destination language.
Decoder-Only Models
Modern LLMs, particularly those in use by the general public such as ChatGPT, are often decoder-only, meaning that there is no discrete encoder as a part of its architecture.
Figuring out how to communicate this difference was a struggle for me initially, but I think it ultimately comes down to how they handle their workloads.
Decoder-only models are streamlined. They don’t split the process into separate encoding and decoding steps but instead handle input processing and output generation simultaneously in a single phase.
If we use the language translation domain as our analogy, its like hearing the source language and translating it to the destination language at the same time.
Decoder-only models depend on the model’s existing embedding space (learned through both pre-training and potentially fine-tuning as discussed above), rather than depending on an encoder to create an intermediary set of embeddings based on the input sequence.
The streamlined nature of decoder-only models allows them to scale up more efficiently, which is beneficial for consumer products like ChatGPT.
This shouldn’t be misunderstood as decoder-only models being less capable, merely that there are some operational efficiencies that can be taken advantage of in a decoder-only setup.
Encoder Layer Elements
Multi-Head Attention
Multi-head attention is essentially a way for the model to understand multiple aspects of the input sequence in parallel using self-attention.
For example, while one head is coming to understand that the “cat” is what is sitting on the “mat”, a second head is simultaneously coming to understand that the “mat” is the thing that the “cat” is sitting on.
Residual Connections (Add)
Residual connections allow the model to pass information from previous layers through to further layers in the architecture. This prevents the model from forgetting information that it already knows while it is working to learn new information about the input sequence.
Residual connections are sometimes also referred to as skip connections, because they allow bits of information to skip the layers ahead of it and be added to the current context as it passes through the layers ahead of it.
Layer Normalization (Norm)
Layer normalization allows the model to achieve a sort of “equilibrium” in the numerical values that it generates during the learning process. Normalization prevents values from becoming too large or too small to be easily handled, which makes its calculations more efficient.
Feed-Forward Neural Networks
Feed-forward neural networks are complex layers that add depth and nuance to information passed through them.
After the attention mechanism identifies the important parts of the input sequence, these layers further refine and interpret this information.
Think of this process as taking a rough sketch, and turning it into a detailed painting.
FFNN layers are where most of the parameter size of a model ends up living, and are where most of the learning happens during training time.
Decoder Layer Elements
Shared Behaviors w/ Encoders
Similarly to their functions in encoder layers, multi-head attention, residual connections, layer normalization, and feed-forward neural networks assist the decoder in arriving at its output representations.
Masked Self-Attention
During training, Masked Self-Attention allows the model to safely predict one token at a time, preventing future tokens from unduly affecting the learning process. During this process, the model can only see the tokens it has already predicted, which helps it predict the next token.
Cross-Attention
Cross-attention (Encoder-Decoder Attention) is the process by which a decoder cross references the embeddings encoded by the encoder layers to help inform its output predictions.
Decoder-only models do not make use of cross-attention (due to there being no discrete encoder layers) and instead rely heavily on self-attention and the model’s existing embedding space to perform the same tasks in a single stage process, like we described earlier.
Output Linear Layer
The output linear layer assigns the initial raw scores to the potential tokens in the output generation process. This connects the high dimensional space of embeddings to the realm of the final output tokens, and runs on the model’s entire vocabulary (its comprehensive set of tokens that can be used to generate text).
Softmax Function
The Softmax function compresses the results of the output linear layer into a distribution of probable tokens. Each probability is represented as a number between 0 and 1. The choice of token in the final output is influenced by the sampling process being used by whichever solution is being run to interact with the model.
Sampling
With the output token probability distribution in hand, we need to perform a technique known as sampling to determine which tokens are chosen for the final output text.
Sampling is not a one-size-fits-all part of the process, as there are many different methods that can be applied to this final distribution.
Temperature is perhaps the most recognizable sampling method. Temperature is essentially a knob that allows for controlling the randomness of the final output text.
As temperature increases, the final output text becomes more random, and as temperature decreases it becomes more conservative, leaning more towards higher probability tokens.
Another popular method of sampling is Top-K. In top-k sampling, the model is restricted to only choosing tokens within a specified number (k) of the most probable tokens.
For example, if Top-K == 40, the model will consider the top 40 most probable tokens, and randomly choose from one of those while selecting the next token in the final output text.
Often, the creativity of the final output text depends on tweaking several stacked sampling methods, rather than depending on a single method such as temperature.
In Conclusion
Now that we’ve explored the primary elements of the architecture from a high level, it’s time to wrap up.
It’s important to note that certain aspects were left out, due to their complexity (dot products, matrix multiplication, specific mathematical concepts around how attention and subsequent layers work, etc.) not fitting the goal of this article.
The actual in-depth math behind how these elements work are better off communicated by someone who specializes in that rather than myself, haha.
However, I hope that I’ve enabled you, at least in part, to see why Transformers represent a major step forward in our journey with artificial intelligence.
While at first glance their complexity can be overwhelming, by using helpful analogies to visualize key aspects of the architecture we can start to approach a general understanding of how the architecture works its magic.
I hope that you’ve found this article as enlightening to read as I found researching and writing it.
If you enjoyed this article, please consider subscribing to my Substack via the button below!
With love,
Christopher (Arki)
Recommended Resources
If you’d like to dig a little bit deeper into this space, I highly recommend the following resources, as they were instrumental in my own learning journey.
Serrano Academy - A truly magnificent communicator, probably my favorite that I have come across. Luis Serrano is extremely talented at communicating complicated concepts, highly recommend watching their series on Transformers.
Jay Alammar - Another excellent communicator, I recommend watching their video on the illustrated Transformer.
AI Explained - Highly recommend their AI Insiders Patreon tier, they’re building up a library of interviews with high profile individuals in the AI industry that are super informative. These are usually interwoven into extended topic focus videos that are easily digestible and well communicated.